~/adi
The best way to try new models
This isn’t a sponsored post.
It seems like a new LLM drops every other day. The latest that piqued my interest was qwq, with “o1-like” reasoning capabilities.
I usually try out new LLMs with Ollama, so satiating my curiosity should have been an ollama run away, but I was too impatient to wait for the 25 GB QwQ to download on 1 MB/s down my hotel WiFi so I figured I’d try something new.
I’ve been a fan of Modal for a while - it’s the simplest way to get from a Python file to a running web service. It’s very useful for running AI workloads easily because you can attach GPUs, and with a generous $30 free credit per month, I can play around with LLMs for free.
There’s an official tutorial for running Ollama on Modal. In minutes, I had Ollama running qwq on a Modal worker, streaming output back to my terminal.
I like to test the “reasoning” capabilities of models with the world’s hardest logic puzzle. qwq struggled with it for 10 minutes before giving up:

Overall, I chatted with it for 18 minutes, which cost me $0.36 on an Nvidia A10G.
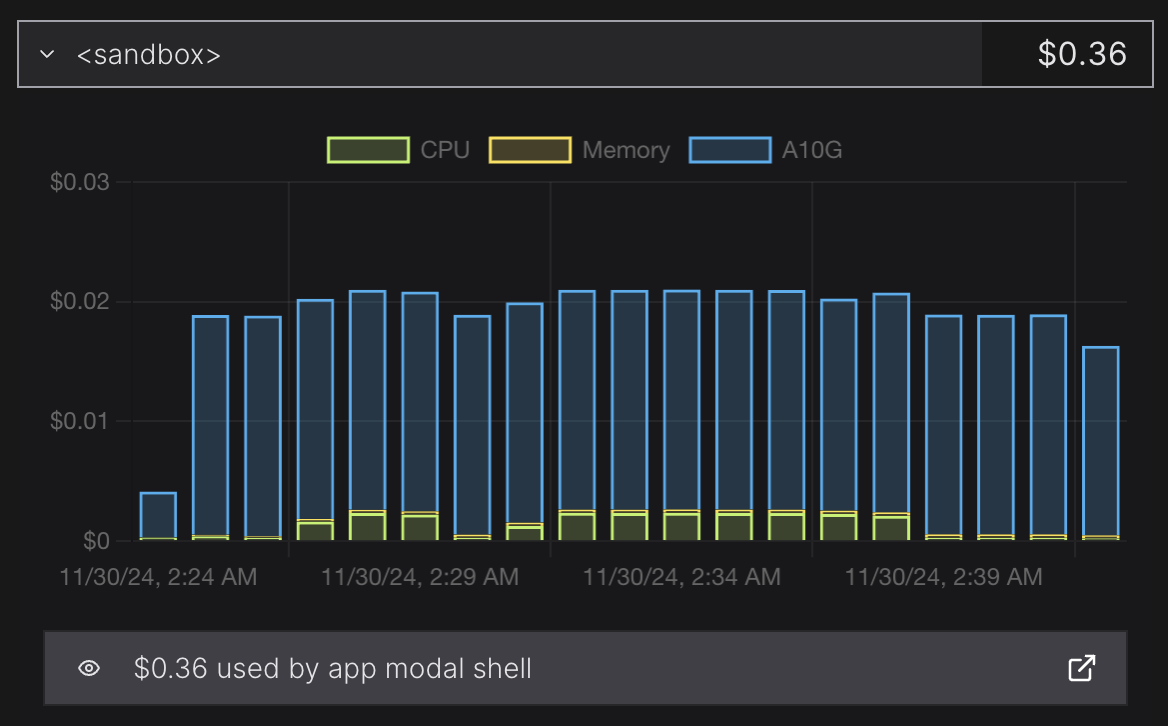
This setup boots in ~15s (the first cold start will take a few minutes due to image build/model download), and Modal only bills for usage so with something like:
modal run ollama-modal.py --text "Your prompt here"
you’re only charged for the time spent on inference, and the worker shuts down once the model finishes outputting.
Modal is also good for more advanced setups e.g. models that aren’t on Ollama, or other serving frameworks. They have several well documented examples for inference and training, and other non-ML workloads, so it’s become go-to for getting something up and running quickly.
I think this Ollama + Modal setup is the easiest and cheapest way to try open-source LLMs, especially if you don’t have the bandwidth to download or hardware to run them yourself.
© 2025 Adi Mukherjee. Credits.