~/adi
Running a local coding agent with LM Studio and OpenCode
I’ve been a huge fan of Claude Code since it launched. Over the past few months, I’ve been using it extensively across all kinds of projects. Claude Code is still the best tool out there, though others (Gemini CLI) are catching up. I recently discovered OpenCode, an open-source model agnostic framework that supports local models, and used it to test gpt-oss-20b, qwen3-coder-30b — currently the best open source coding models with tool calling.
This tutorial covers setting up OpenCode with LM Studio for local inference on a single machine.
Setup
LMStudio
Ollama is very popular, but I use LM Studio because it has a nice UI and an MLX runtime which is very efficient for inference on Apple Silicon.
- Download LM Studio
- Switch to Developer mode at the bottom left

- If you’re on Apple Silcon, ensure you have the MLX backend installed
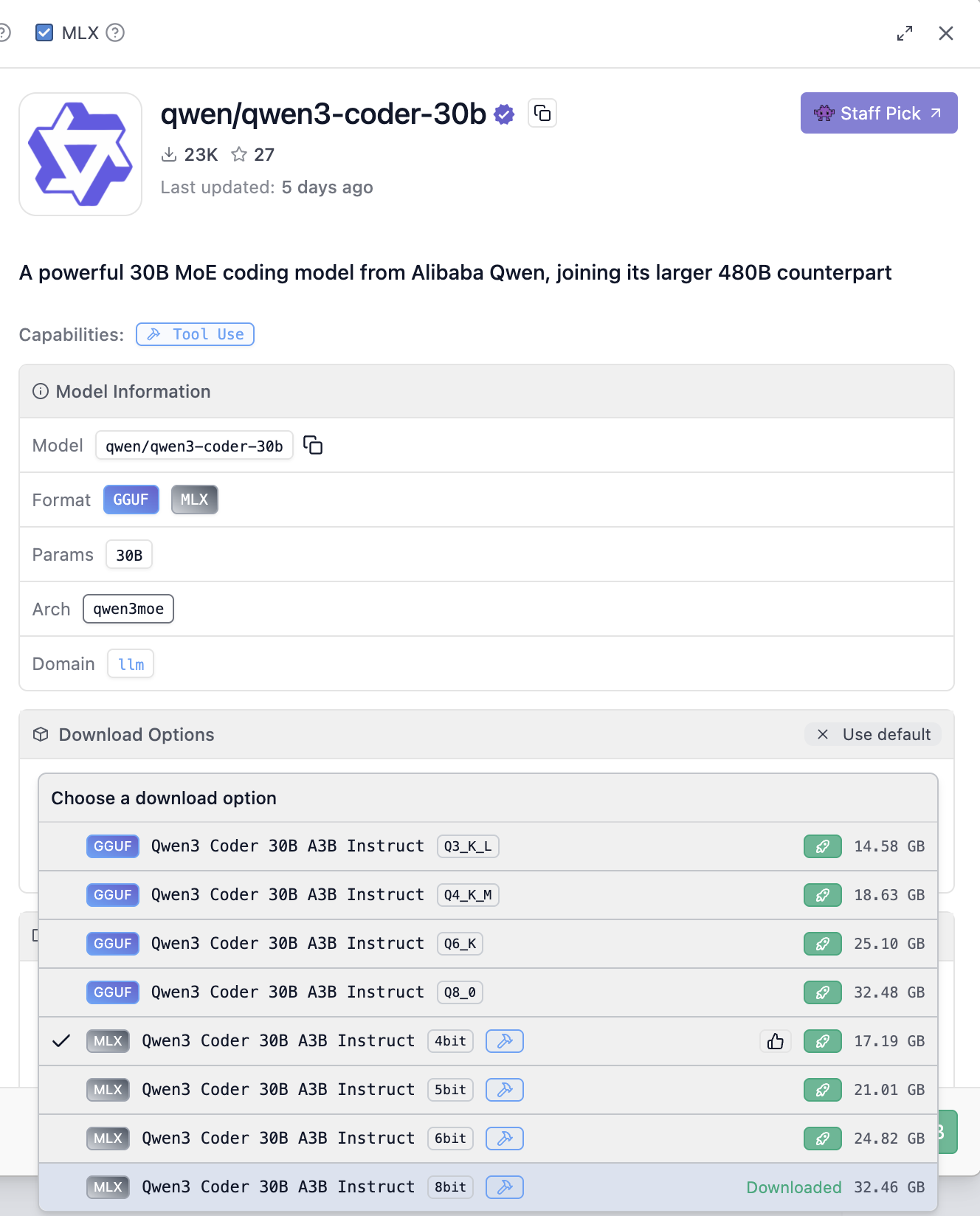
- Download the right version of the model for your hardware
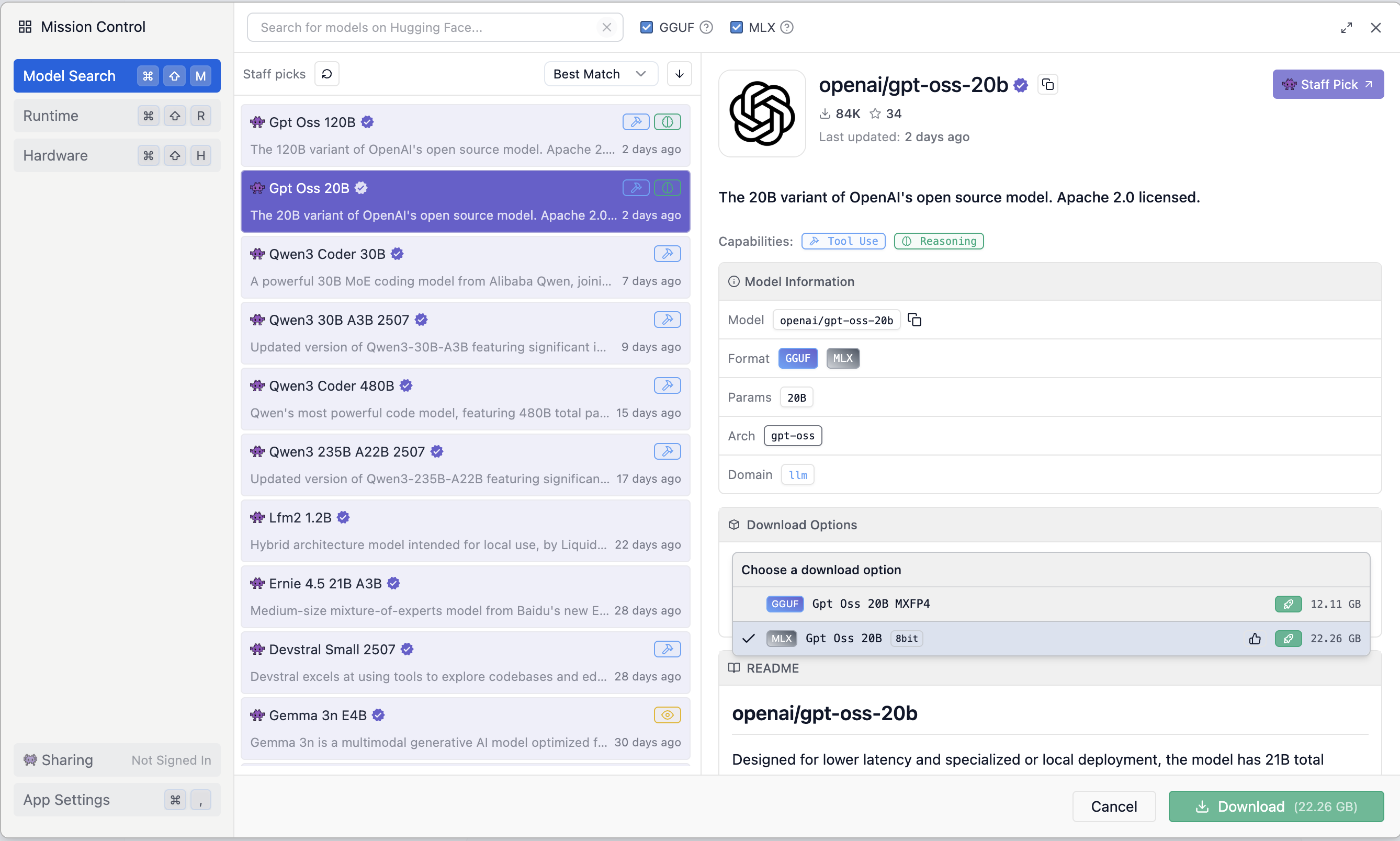
- Go for the highest memory footprint you can fit on your hardware for best capabilities, the lowest for fastest inference
- Run the LM Studio server
- Load the model. Set the context window to at least 16k, otherwise there isn’t enough context for OpenCode’s prompts. Save these params for future.
- Test it works - copy the URL shown in
Reachable atand curl/v1/models
Fix qwen3-coder tool calling format
qwen3-coder with LMStudio’s default system prompt template outputs tool calls as XML while OpenCode expects JSON.
This isn’t an issue with gpt-oss as it uses the new JSON-based Harmony format.

Fix it by replacing the default template with one like this and reloading the model.
OpenCode
- Install OpenCode
- Create a config file at
~/.config/opencode/opencode.jsonwith the following, replacing$BASE_URLwith the “Reachable At” URL from LM Studio:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"lmstudio": {
"npm": "@ai-sdk/openai-compatible",
"name": "LM Studio (local)",
"options": {
"baseURL": "$BASE_URL/v1"
},
"models": {
"openai/gpt-oss-20b": {
"name": "gpt-oss-20b"
},
"qwen/qwen3-coder-30b": {
"name": "qwen3-coder-30b"
}
}
}
}
}
- Run
opencodeand/modelto select the model. It’ll be listed underLM Studio (local) - Keen an eye on the LM Studio server logs for any errors
- Enjoy!
Hosting the model on another machine
I use an M4 Pro Mac Mini as a home server, on which I host many services. The LM Studio server is the latest one, which I use to drive OpenCode, Open Webui, llm, and call from other codebases. All my devices are connected via Tailscale, so the only change to these instructions is to set baseURL in the OpenCode config to the tailscale serve URL instead of the one from LM Studio.
Review
Capabilities
I’ve tested both qwen3-coder-30b and gpt-oss-20b on menial tasks I normally use Claude Code for:
- vibe coding a simple idea as a demo
- compressing GIFs to a certain size
- explaining what’s going on a repo/directory
These workflows expose the gap between Claude Code and local models: while qwen3-coder and gpt-oss can make tool calls, they lack Claude’s intelligent tool selection and the framework’s reliability.
I also tested these workflows with gpt-oss-120b hosted on Cerebras, which is supposed to match o4-mini. It did well at coding and explaining, but couldn’t complete the GIF compression task.
I highly recommend trying a Cerebras backend, with OpenCode, Cline, or their playground - the speed is incredible and it’s got a free tier. Claude Code with such performance would be magical, no more waiting for responses.
Performance
Apple Silicon is very different from Nvidia hardware. With any local model, especially with a long context window, prefill is slow — often tens of seconds as context grows. But decoding is surprisingly fast. Simple Q&A prompts can actually run faster than Claude—without tool use or complex reasoning, you’re eliminating network latency while running a smaller, faster model than 4.1 Opus.
Here’s an example of the memory usage on my Mac Mini with loading and chatting with gpt-oss-20b, with llm to make requests and asitop to profile.
llm
llm is a fantastic tool with a rich plugin ecosystem that makes running simple prompts like this effortless. Here’s a quick guide to setting it up with LM Studio:
- install
llm - go to
dirname "$(llm logs path)" - create
extra-openai-models.yamlwith contents:
- model_id: gpt-20b
model_name: openai/gpt-oss-20b
api_base: "https://<api_url>/v1"
- run it with
llm -m gpt-20b '<your prompt here>'
Looking Forward
qwen3-coder-30b and gpt-oss-20b are the best open-source coding models I’ve tested at their parameter ranges. While this setup isn’t ready to replace Claude Code for daily work, it’s surprisingly capable for specific workflows. The real value is in rapid experimentation — when a new model drops, I can test it within minutes using familiar tools.
Next, I want to design a set of evals - not rigorous performance benchmarks, but small, self-contained, real world tasks like the above or Simon Willison’s SVG of a pelican on a bicycle or space invaders game, as a measure of how ready these models & frameworks are to migrate workflows off the cloud.
If there are any bugs in this tutorial, or if you have anything to add, please email or DM me.
© 2025 Adi Mukherjee. Credits.